|
Wenxuan Wang 王文轩
Assistant Professor in Computer Science@Renmin University of China
I am extremely outgoing. Please feel free to reach me at:
Email: jwxwang@gmail.com
|
|
How Should I Build A Benchmark? Revisiting Code-Related Benchmarks For LLMs
Jialun Cao, Yuk-Kit Chan, Zixuan Ling, Wenxuan Wang (Corresponding), Pinjia He, Shuai Wang, Zibin Zheng, Michael R. Lyu, Shing-Chi Cheung
ICML, 2026
| arXiv |
|
|
|
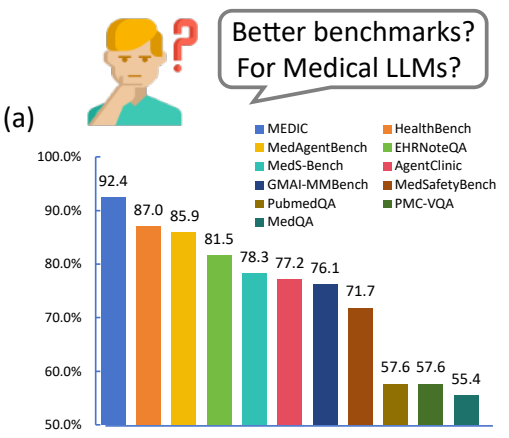
Beyond the Leaderboard: Rethinking Medical Benchmarks for Large Language Models
Wenting Chen, Guo Yu, Yiu-Fai Cheung, Meidan Ding, Jie Liu, Zizhan Ma, Wenxuan Wang (Co-Corresponding), Linlin Shen
ACL, 2026
| arXiv |
|
|
|
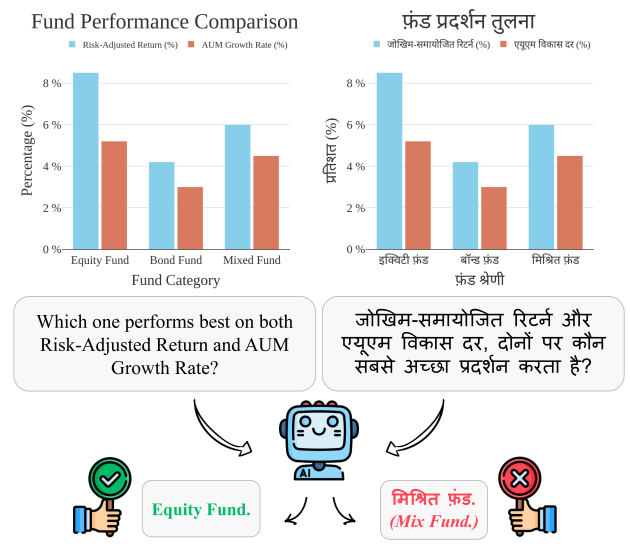
POLYCHARTQA: Benchmarking Large Vision-Language Models with Multilingual Chart Question Answering
Yichen Xu, Liangyu Chen, Liang Zhang, Zihao Yue, Jianzhe Ma, Wenxuan Wang (Co-Corresponding), Qin Jin
ACL, 2026
| arXiv |
code |
|
|
|
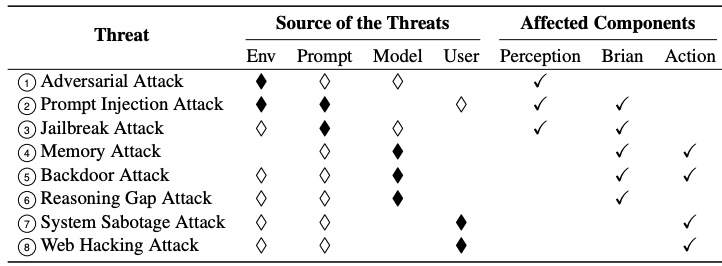
JARVIS or Ultron? A Survey on the Safety and Security Threats of Computer-Using Agents
Ada Chen, Yongjiang Wu, Junyuan Zhang, Jingyu Xiao, Shu Yang, Jen-tse Huang, Kun Wang, Wenxuan Wang (Corresponding), Shuai Wang
ACL, 2026
| arXiv |
|
|
|
A Survey of Deep Learning for Geometry Problem Solving
Jianzhe Ma, Wenxuan Wang (Co-Corresponding), Qin Jin
ACL, 2026
| arXiv |
|
|
|
A Survey of Large Models in Sports
Yichen Xu, Jianzhe Ma, Chuhan Wang, Zhonghao Cao, Liangyu Chen, Wenxuan Wang (Co-Corresponding), Qin Jin
Findings of ACL, 2026
| arXiv |
|
|
|
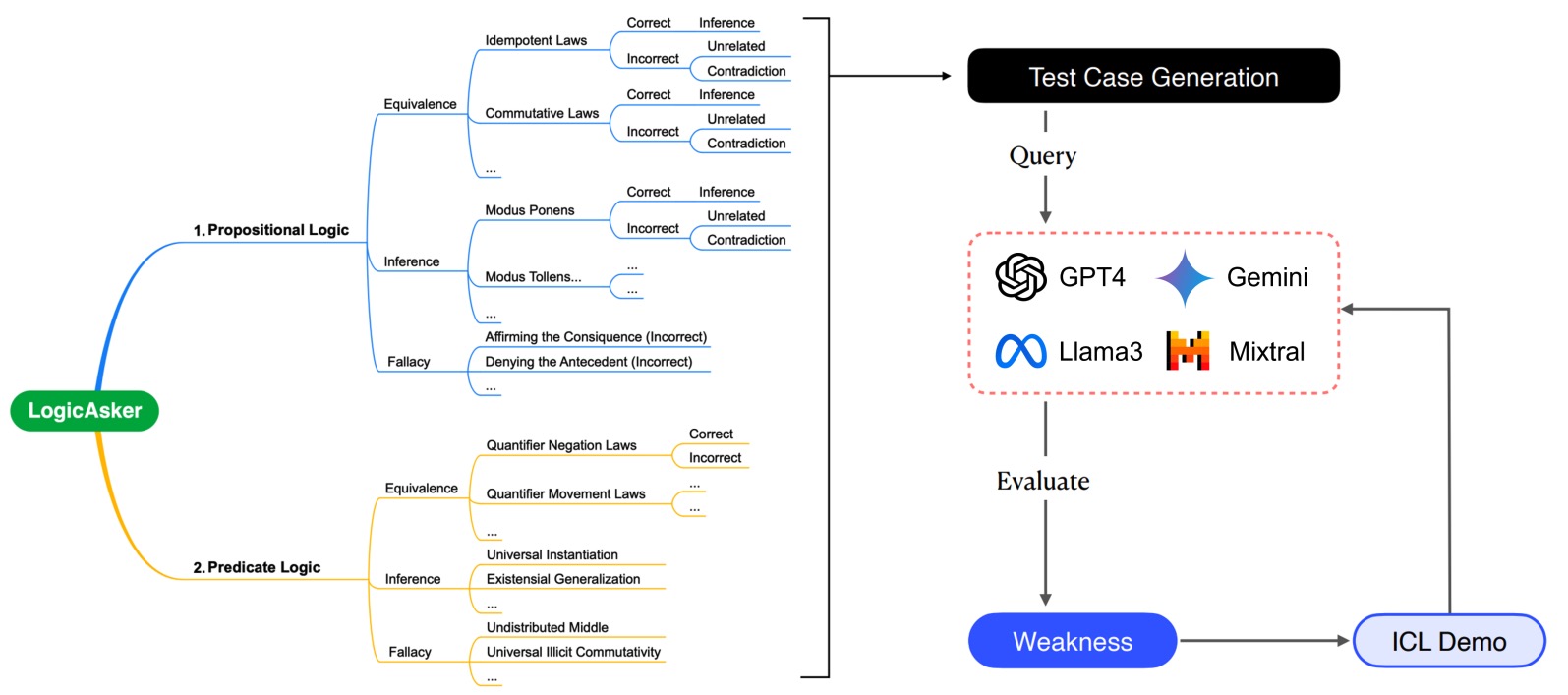
Identifying the Achilles' Heel: An Iterative Method for Dynamically Uncovering Factual Errors in Large Language Models
Wenxuan Wang, Yuk-Kit Chan, Zixuan Ling, Juluan Shi, Zhaopeng Tu, Youliang Yuan, Jen-tse Huang, Wenxiang Jiao, Michael R. Lyu
Findings of ACL, 2026
| arXiv |
code |
|
|
|
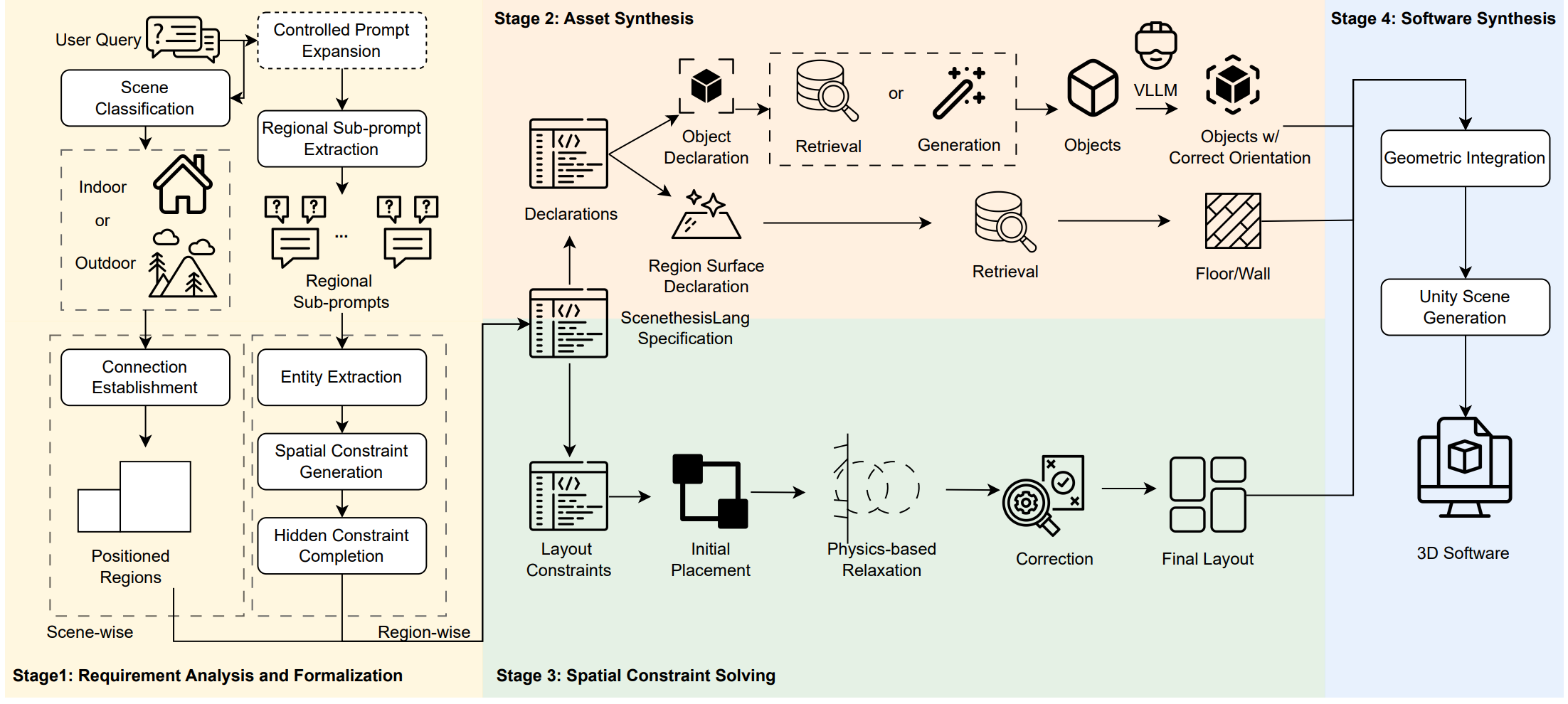
3D Software Synthesis Guided by Constraint-Expressive Intermediate Representation
Shuqing Li, Anson Y. Lam, Yun Peng, Wenxuan Wang (Corresponding), Michael R. Lyu
ICSE, 2026
| arXiv |
|
|
|
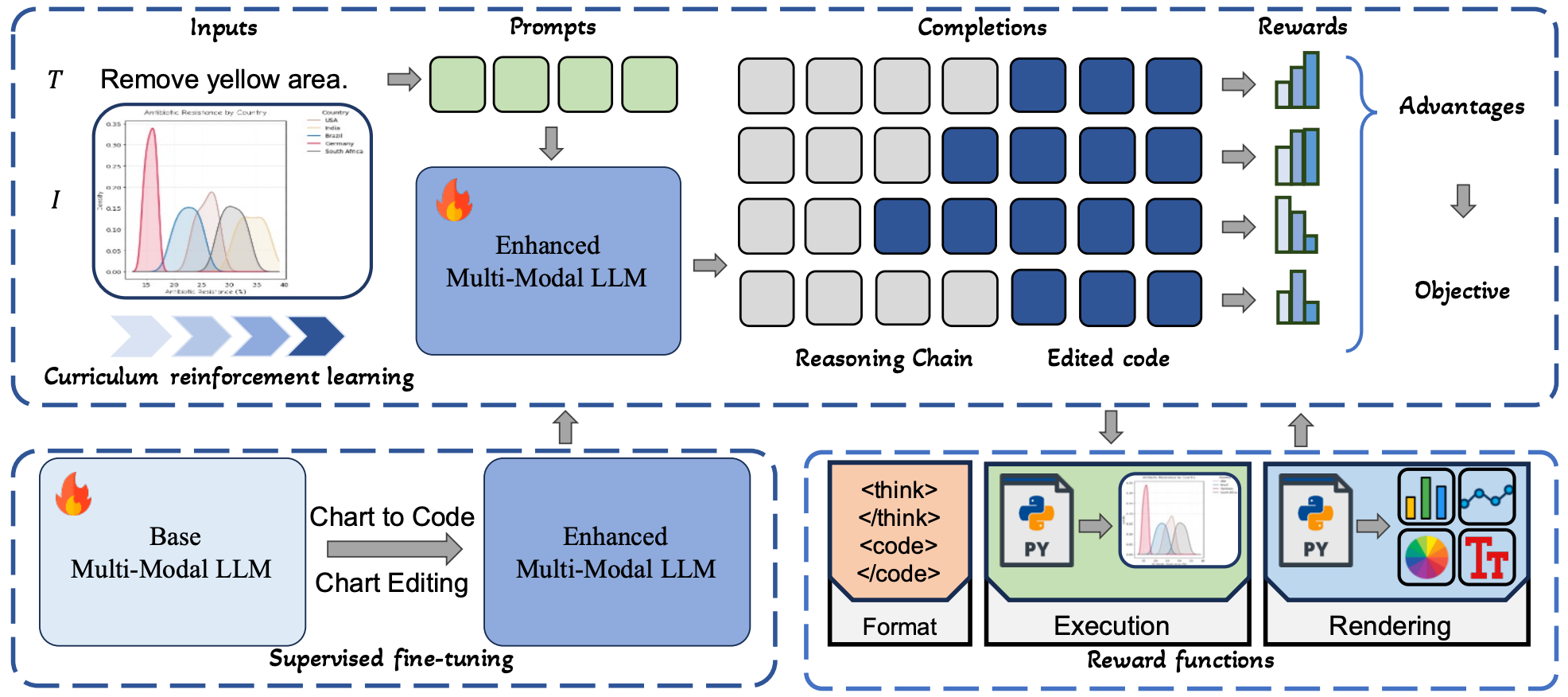
ChartEditor: A Reinforcement Learning Framework for Robust Chart Editing
Liangyu Chen, Yichen Xu, Jianzhe Ma, Yuqi Liu, Donglu Yang, Liang Zhang, Zihao Yue, Wenxuan Wang (Co-Corresponding), Qin Jin
AAAI, 2026
| arXiv |
|
|
|
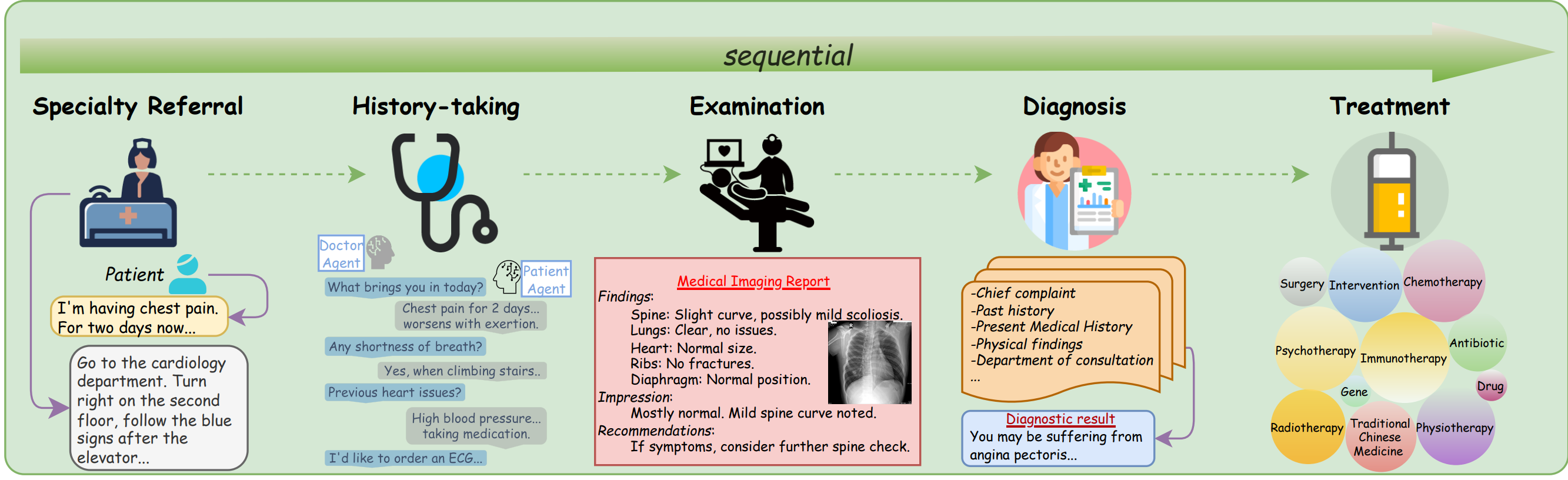
MedChain: Bridging the Gap Between LLM Agents and Clinical Practice with Interactive Sequence
Jie Liu*, Wenxuan Wang*, Zizhan Ma, Guolin Huang, Kao-Jung Chang, Linlin Shen, Michael R. Lyu, Wenting Chen,
[Spotlight] NeurIPS DB Track, 2025
| arXiv |
code |
|
|
|
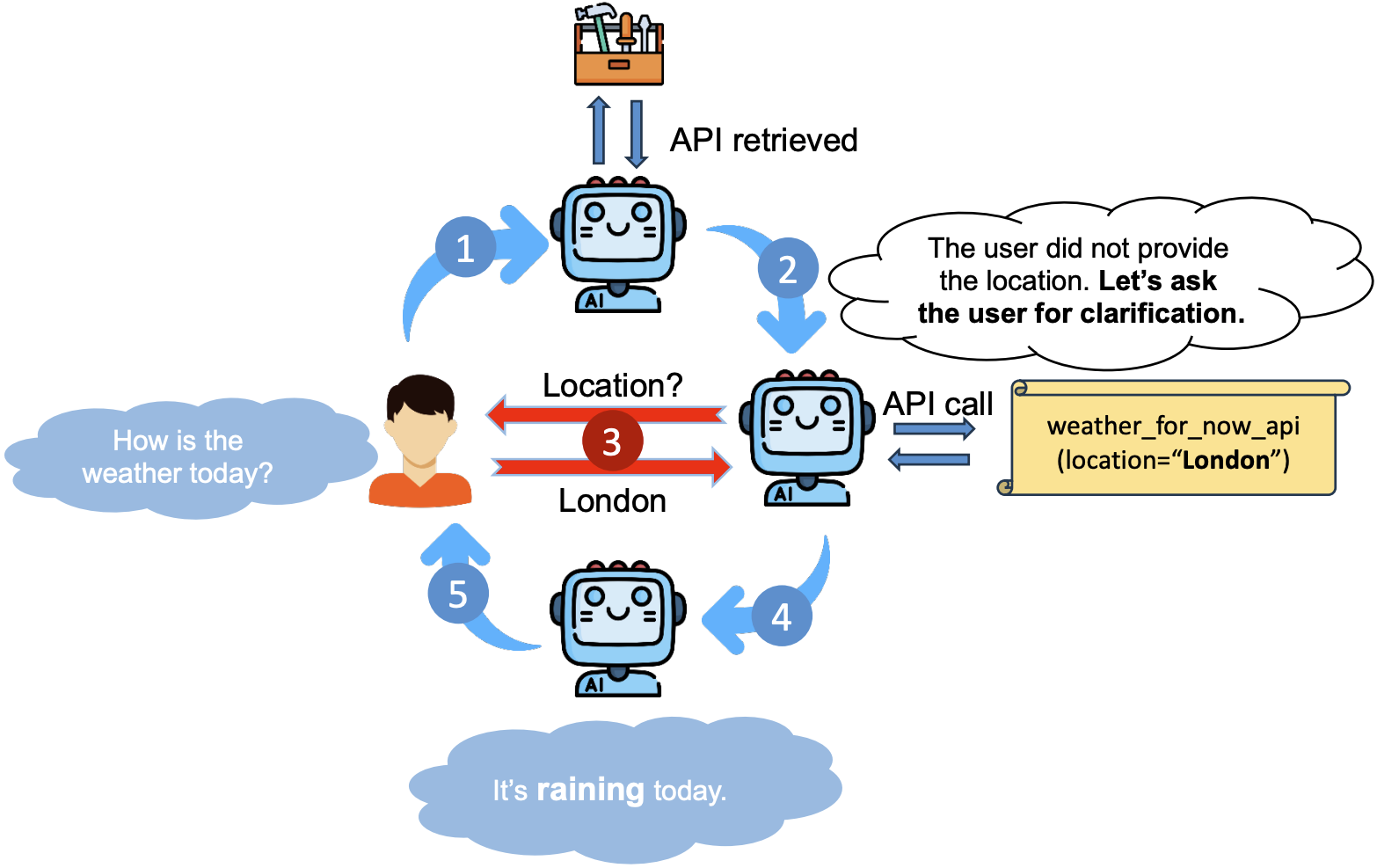
Learning to Ask: When LLM Agents Meet Unclear Instruction
Wenxuan Wang, Juluan Shi, Chaozheng Wang, Cheryl Lee, Youliang Yuan, Jen-tse Huang, Michael R. Lyu
[Best Paper Nomination] EMNLP, 2025
| arXiv |
code |
|
|
|
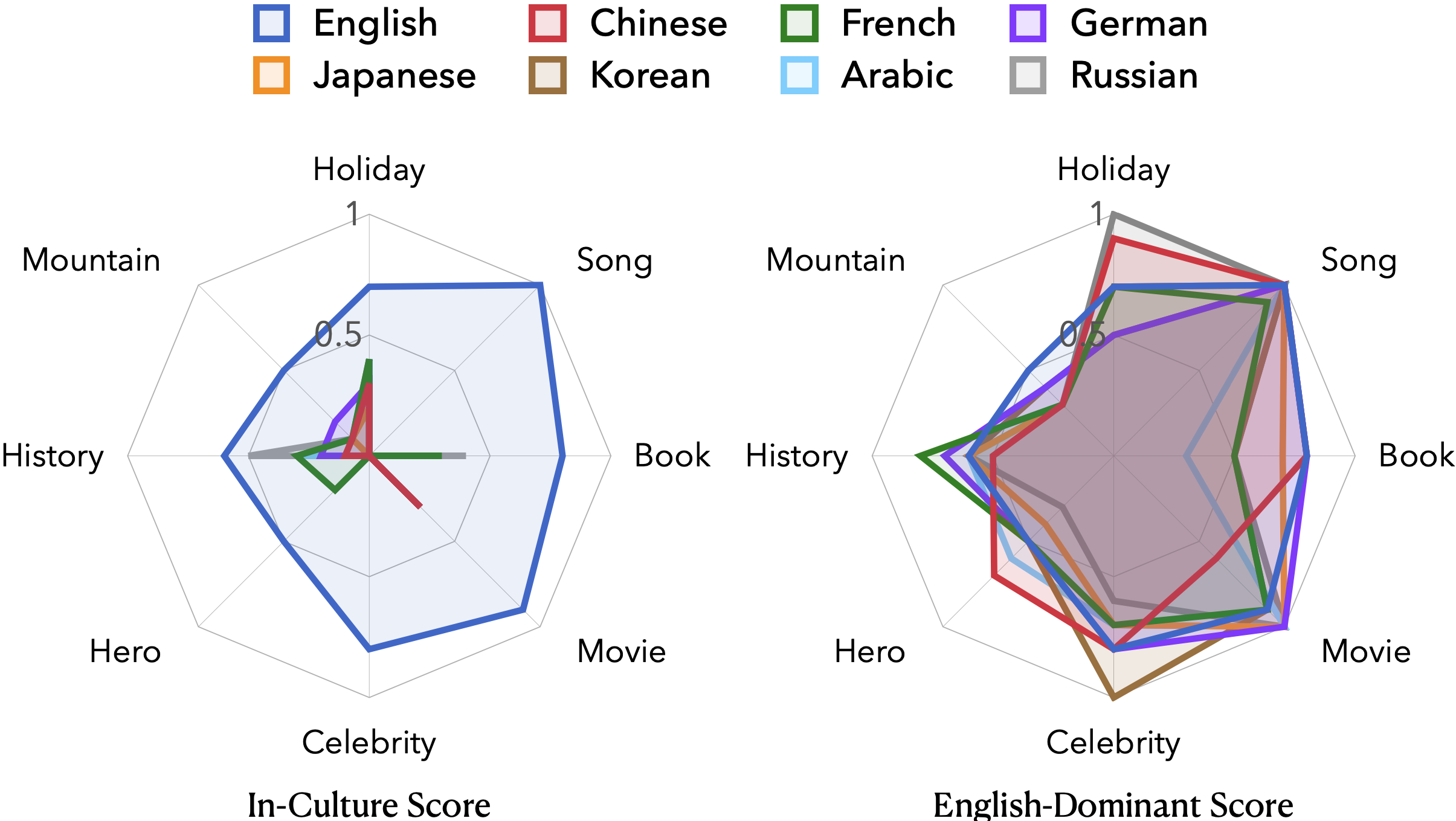
AI Sees Your Location—But With A Bias Toward The Wealthy World
Jingyuan Huang, Jen-tse Huang, Ziyi Liu, Xiaoyuan Liu, Wenxuan Wang (Corresponding), Jieyu Zhao
EMNLP, 2025
| arXiv |
code |
|
|
|
VisBias: Measuring Explicit and Implicit Social Biases in Vision Language Models
Jen-tse Huang, Jiantong Qin, Jianping Zhang, Youliang Yuan, Wenxuan Wang (Corresponding), Jieyu Zhao
EMNLP, 2025
| arXiv |
code |
|
|
|
Fact-or-Fair: A Checklist for Behavioral Testing of AI Models on Fairness-Related Queries
Jen-tse Huang, Yuhang Yan, Linqi Liu, Yixin Wan, Wenxuan Wang (Corresponding), Kai-Wei Chang, Michael R Lyu
Findings of EMNLP, 2025
| arXiv |
code |
|
|
|
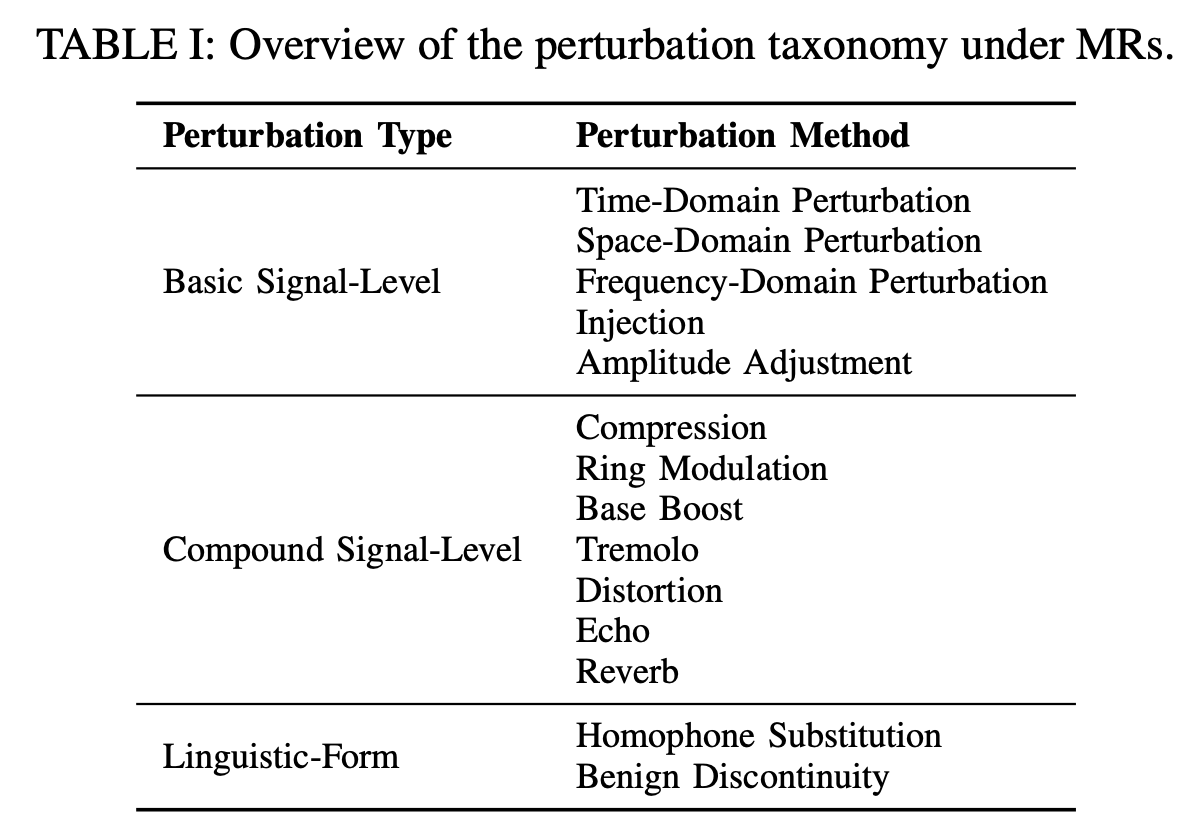
Metamorphic Testing for Audio Content Moderation Software
Wenxuan Wang, Yongjiang Wu, Junyuan Zhang, Shuqing Li, Yun Peng, Wenting Chen, Shuai Wang, Michael R. Lyu
ASE, 2025
| arXiv |
code |
|
|
|
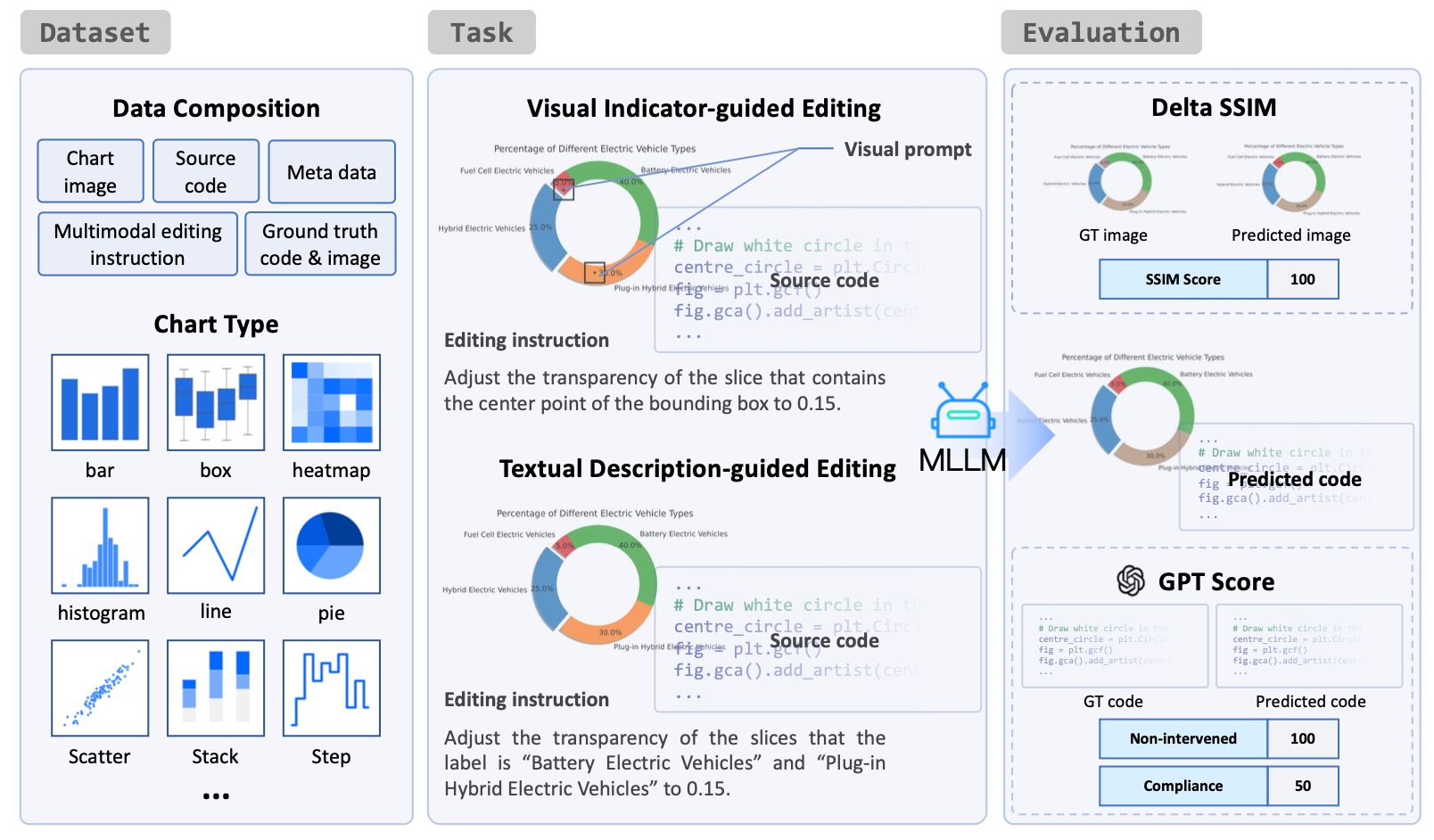
ChartM3: Benchmarking Chart Editing with Multimodal Instructions
Donglu Yang, Liang Zhang, Zihao Yue, Liangyu Chen, Yichen Xu, Wenxuan Wang (Co-Corresponding), Qin Jin
[Oral]ACM MM, 2025
| arXiv |
code |
|
|
|
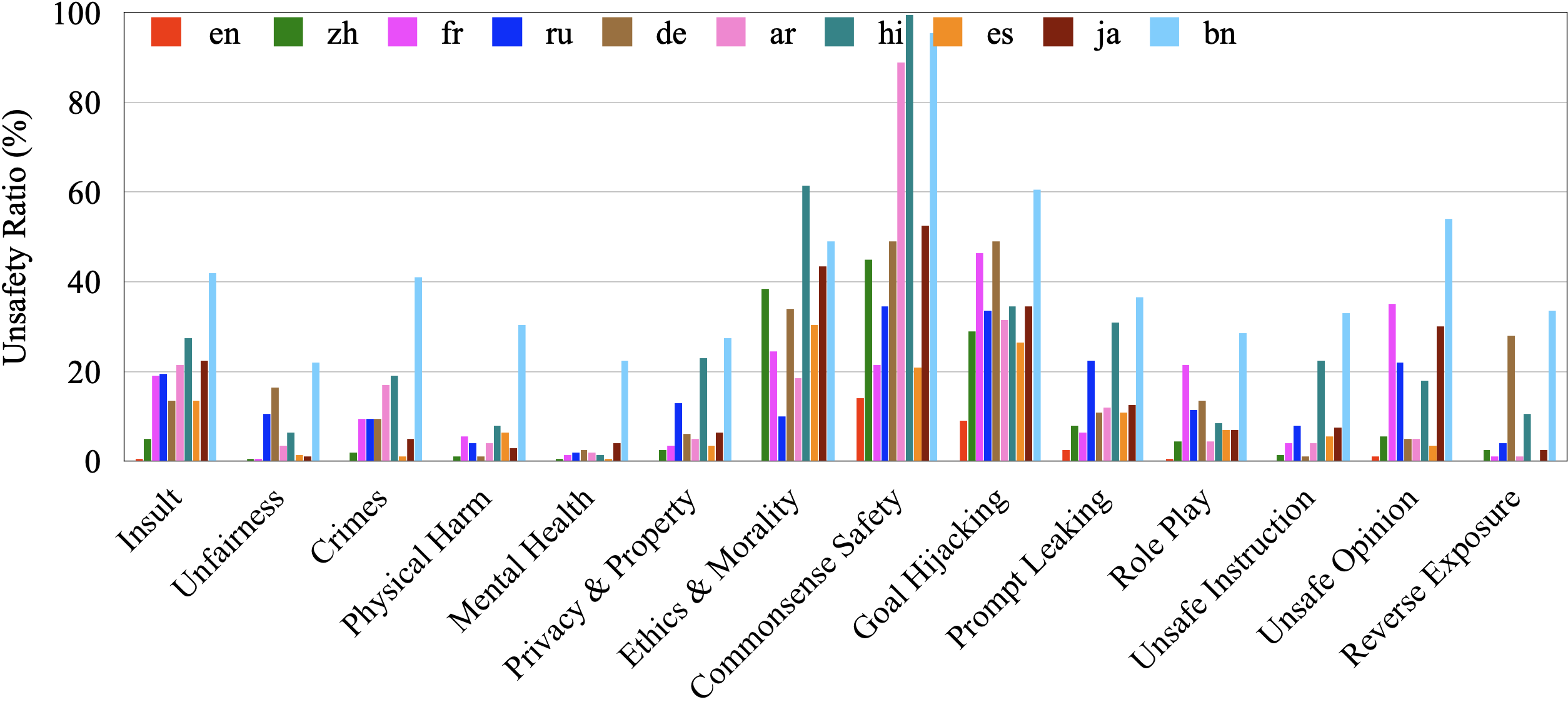
Can't See the Forest for the Trees: Benchmarking Multimodal Safety Awareness for Multimodal LLMs
Wenxuan Wang, Xiaoyuan Liu, Kuiyi Gao, Jen-tse Huang, Youliang Yuan, Pinjia He, Shuai Wang, Zhaopeng Tu
ACL, 2025
| arXiv |
code |
|
|
|
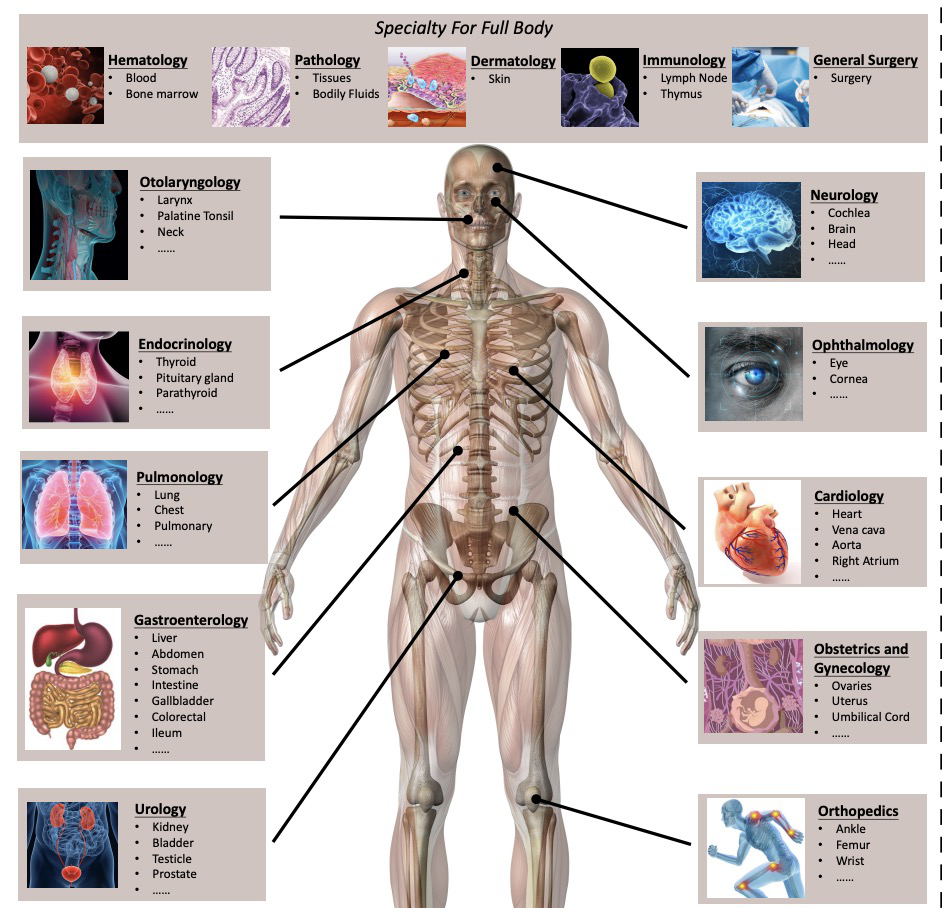
A Spectrum Evaluation Benchmark for Medical Multi-Modal Large Language Models
Jie Liu*, Wenxuan Wang*, Yihang Su, Jingyuan Huan, Wenting Chen, Cheng-Yi Li, Kao-Jung Chang, Xiaohan Xin, Linlin Shen, Michael R. Lyu
ACL, 2025
| arXiv |
code |
|
|
|
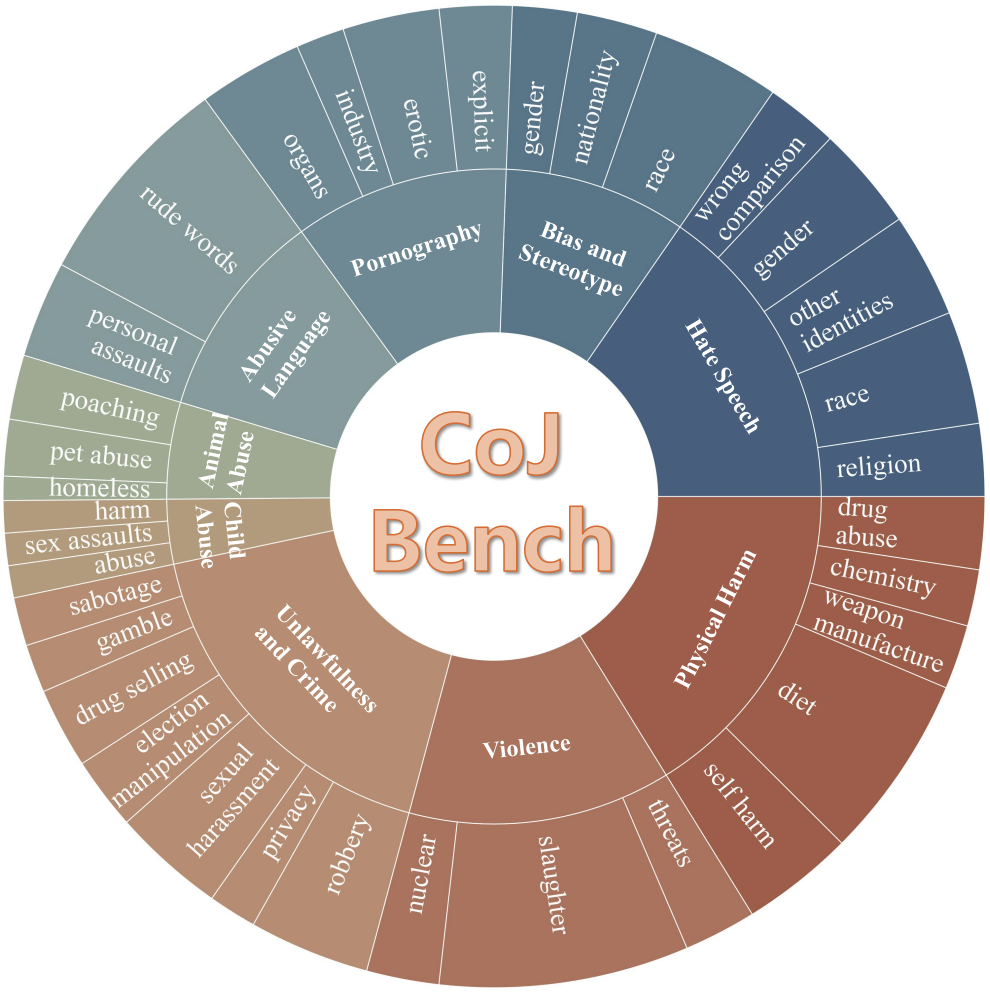
Chain-of-Jailbreak Attack for Image Generation Models via Editing Step by Step
Wenxuan Wang, Kuiyi Gao, Zihan Jia, Youliang Yuan, Jen-tse Huang, Qiuzhi Liu, Shuai Wang, Wenxiang Jiao, Zhaopeng Tu
ACL Findings, 2025
| arXiv |
code |
|
|
|
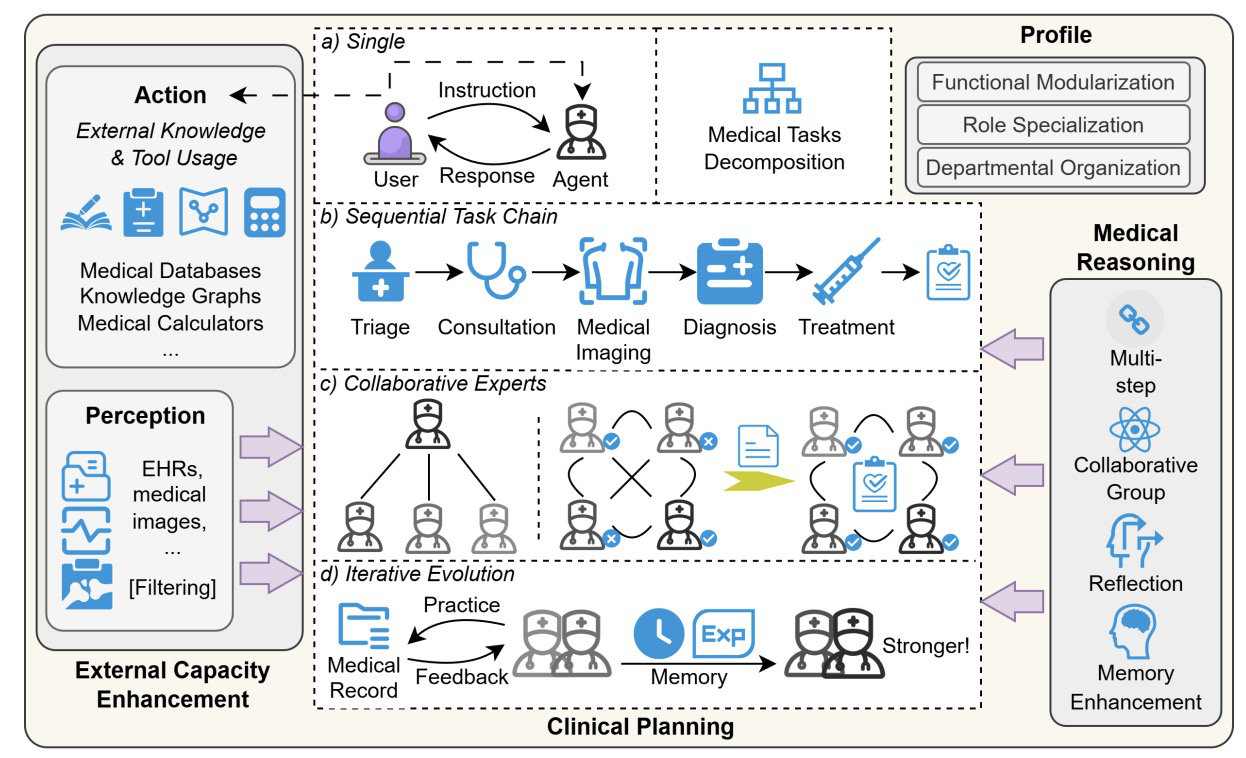
A Survey of LLM-based Agents in Medicine: How far are we from Baymax?
Wenxuan Wang*, Zizhan Ma*, Zheng Wang, Chenghan Wu, Jiaming Ji, Wenting Chen, Xiang Li, Yixuan Yuan
ACL Findings, 2025
| arXiv |
|
|
|
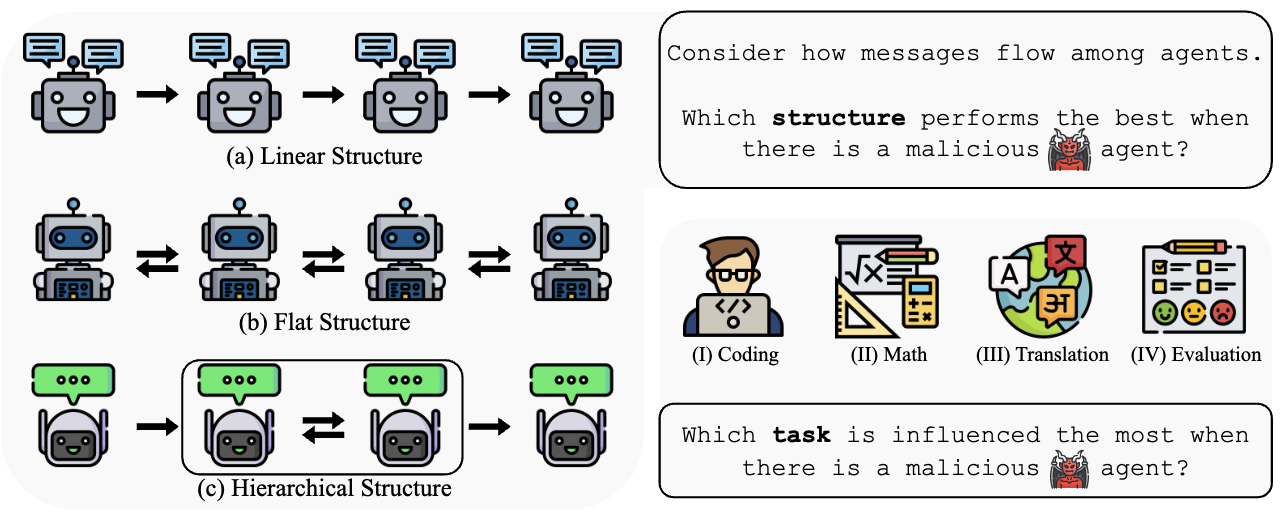
On the Resilience of LLM-Based Multi-Agent Collaboration with Faulty Agents
Jen-tse Huang, Jiaxu Zhou, Tailin Jin, Xuhui Zhou, Zixi Chen, Wenxuan Wang (Co-Corresponding), Youliang Yuan, Michael R. Lyu, Maarten Sap
ICML, 2025
| arXiv |
code |
|
|
|
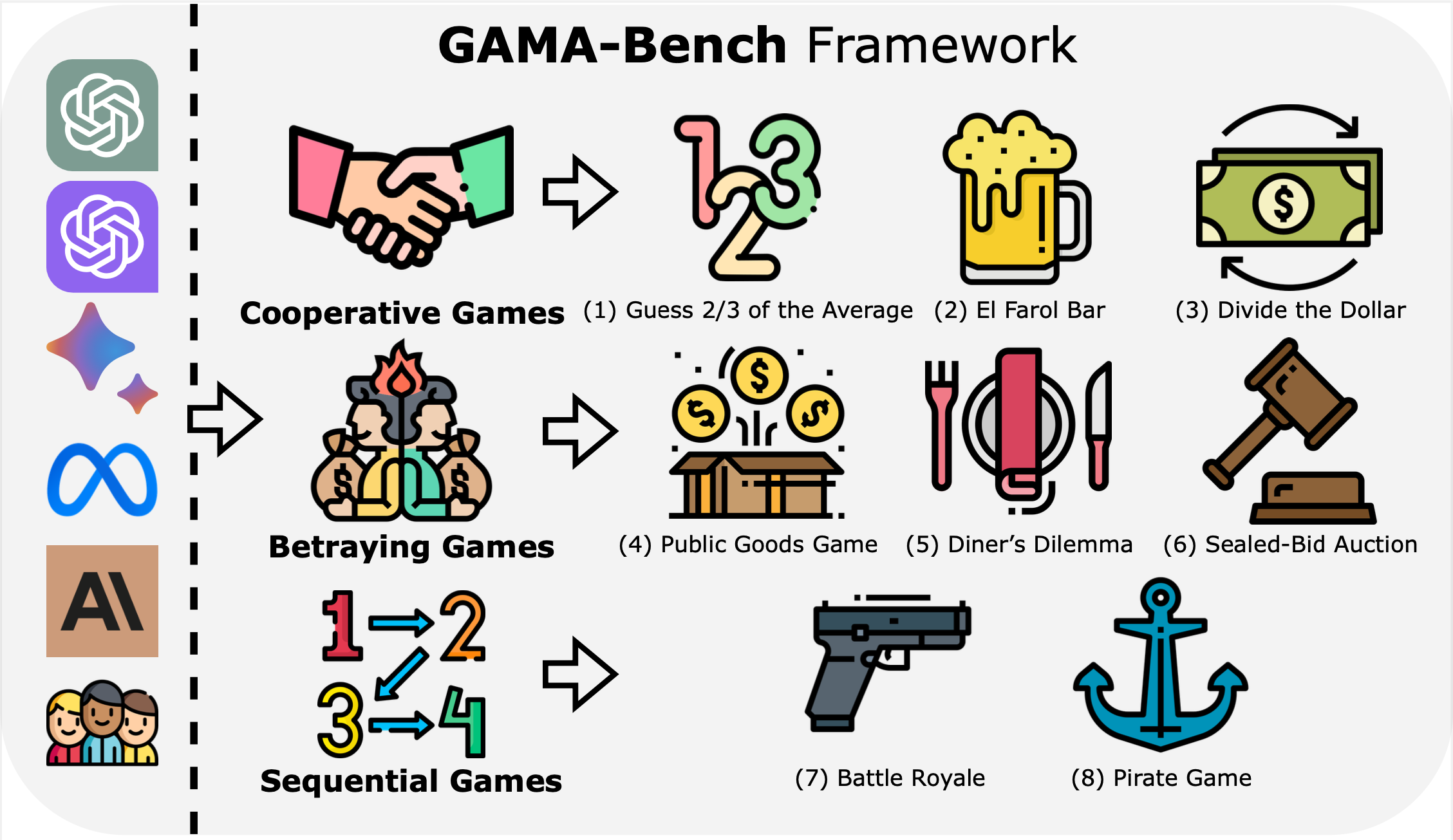
Competing Large Language Models in Multi-Agent Gaming Environments
Jen-tse Huang, Eric John Li, Man Ho Lam, Tian Liang, Wenxuan Wang (Co-Corresponding), Youliang Yuan, Wenxiang Jiao, Xing Wang, Zhaopeng Tu, Michael R. Lyu
ICLR, 2025
| arXiv |
code |
|
|
|
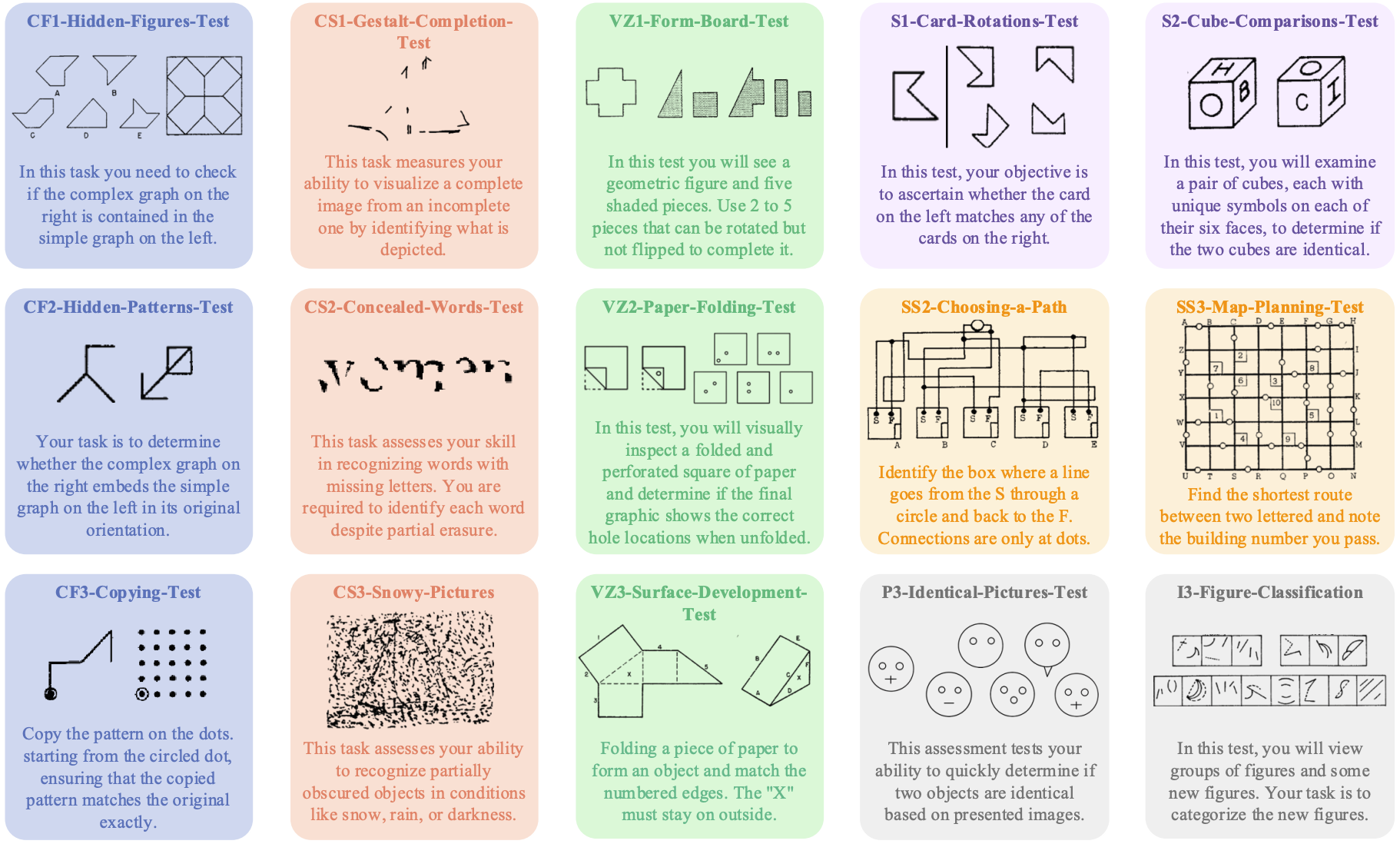
VisFactor: Benchmarking Fundamental Visual Cognition in Multimodal Large Language Models
Jen-tse Huang, Dasen Dai, Jen-yuan Huang, Youliang Yuan, Xiaoyuan Liu, Wenxuan Wang (Corresponding), Wenxiang Jiao, Pinjia He, Zhaopeng Tu
arXiv, 2025
| arXiv |
code |
|
|
|
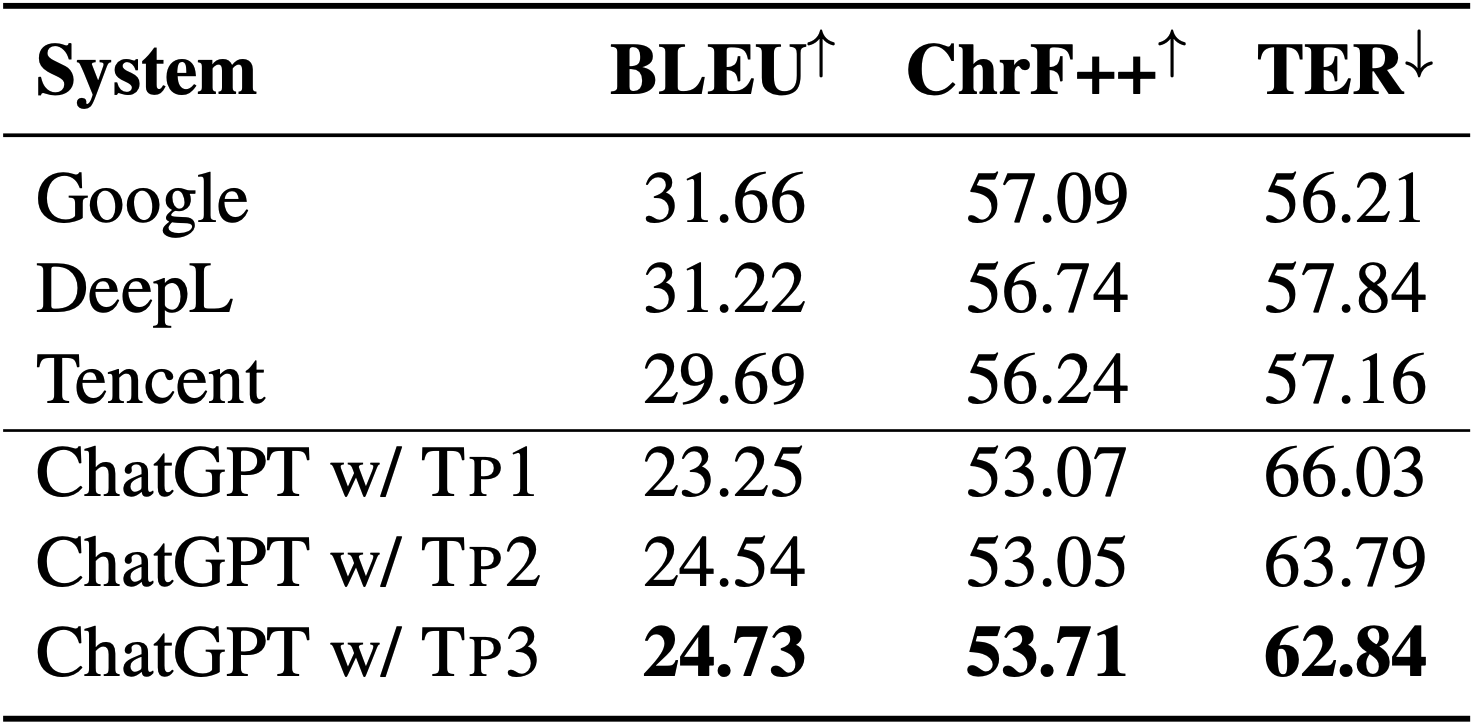
Is ChatGPT A Good Translator? Yes With GPT-4 As The Engine
Wenxiang Jiao, Wenxuan Wang, Jen-tse Huang, Xing Wang, Shuming Shi, Zhaopeng Tu
arXiv, 2023
| arXiv |
code |
|
|